Millions of weather observations taken over a century ago are not available to climate scientists as they only exist as hand-written measurements in various logbooks stored in archives around the world. GloSAT used a ‘citizen science’ approach to recover observations and make them usable.
The focus for data rescue was on measurements taken on board ships travelling through the Atlantic, Indian and Pacific ocean basins in the Weather Rescue at Sea project, and from an NOAA-led Old Weather – WWII citizen science zooniverse project. GloSAT also funded research to accelerate the development of automated approaches to extracting data.
There were three strands to the GloSAT data-rescue activities:
- Weather rescue at sea,
- Old Weather – WWII data,
- Using AI to transcribe data
1. Weather Rescue at Sea
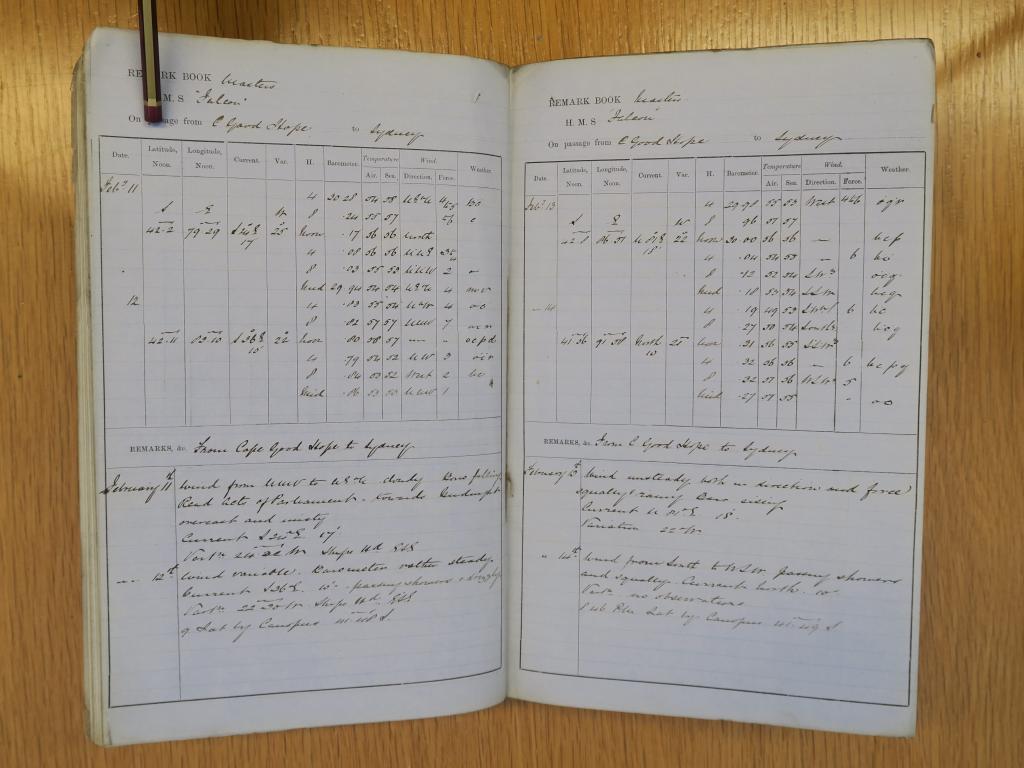
A new citizen-science project, Weather Rescue at Sea, was hosted on zooniverse. It filled some of the gaps in space and time in global climate datasets by strategically prioritizing logbooks, focusing on those containing at least air temperature (AT) or sea-surface temperature (SST) observations. Logbooks (Figure 2) archived at the UK Hydrographic Office (UKHO) are best suited to produce data in the early-industrial time period with global coverage. They contain six, 4-hourly, meteorological observations per day.
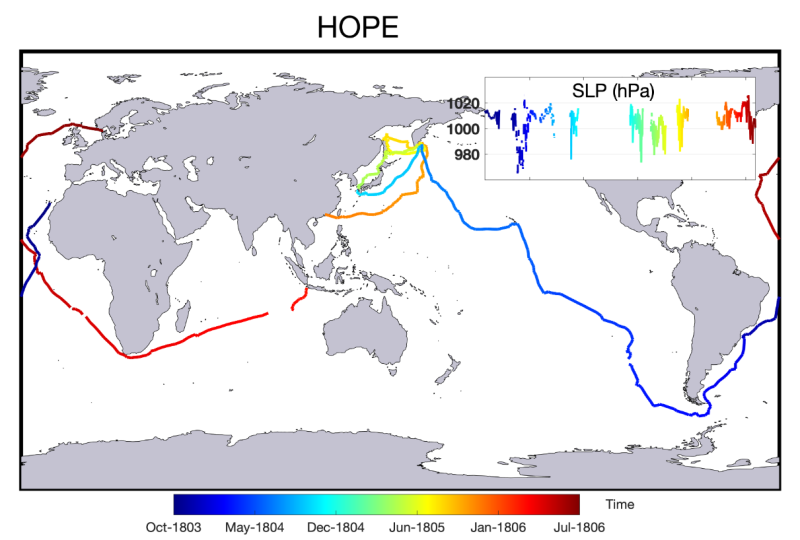
2. Old Weather – WWII data
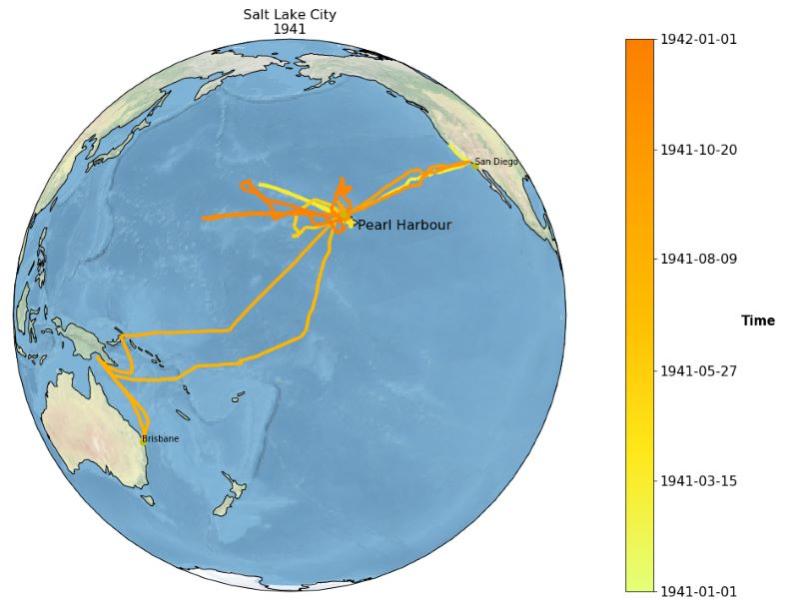
The Old Weather – WWII citizen science zooniverse project, led by NOAA, involves the transcription of US cruiser and destroyer logbooks (deployed during WWII) by volunteers. These logbooks contain 4-hourly meteorological observations, with parameters including sea-level pressure (SLP), air temperature (AT) and sea-surface temperature (SST). These vessels traversed mainly the Pacific and Atlantic Oceans (figure 4). The transcribed data generated through the zooniverse platform is processed and quality controlled, producing invaluable WWII daily weather data.
3. Using AI to transcribe data
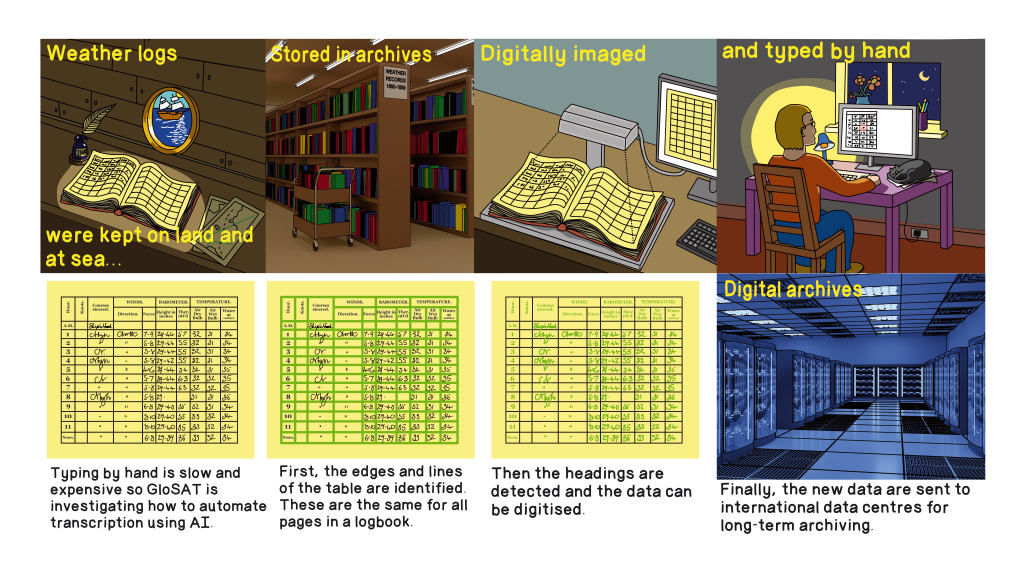
Extracting information from images of logbooks in traditional ways is time consuming and expensive. GloSAT funded research into improving the automatic extraction of data. Automatic extraction, for example using AI techniques, is particularly difficult for cases of hand written tabular data. In these cases the text or numbers may cross the lines of the table and be hard to read, and often in tabular data gaps have meaning so need to be identified and handled correctly.
Associated publications
| Author/Title | PlumX | Altmetrics |
|---|---|---|
| P. Teleti, E. Hawkins, C. Wilkinson (2026) Weather Rescue at Sea: Recovering Historical Weather Observations From 19th Century British Naval Ships, Geoscience Data Journal, doi:10.1002/gdj3.70056 | ||
| J. Luterbacher, R. Allan, C. Wilkinson, E. Hawkins, P. Teleti, A. Lorrey, S. Brönnimann, P. Hechler, K. Velikou, E. Xoplaki (2024) The Importance and Scientific Value of Long Weather and Climate Records; Examples of Historical Marine Data Efforts across the Globe, Climate, 12, 39, doi:10.3390/cli12030039 | ||
| E. Hawkins, P. Brohan, S.N. Burgess, S. Burt, G.P. Compo, S.L. Gray, I.D. Haigh, H. Hershbach, K. Kuijjer, O. Martinez-Alvarado, C. McColl, A.P. Schurer, L. Slivinski, J. Williams (2023) Rescuing historical weather observations improves quantification of severe windstorm risks, Natural Hazards and Earth System Sciences, doi:10.5194/nhess-23-1465-2023 | ||
| P. Teleti, E. Hawkins, K.R. Wood (2023) Digitizing weather observations from World War II US naval ship logbooks, Geoscience Data Journal, doi:10.1002/gdj3.222 | ||
| S. Middleton J. Ziomek (2021) GloSAT Historical Measurement Table Dataset: Enhanced table structure recognition annotation for downstream historical data rescue, International Workshop on Historical Document Imaging and Processing, Lausanne, Switzerland. 5–6 Sep 2021 https://eprints.soton.ac.uk/450279 |
Associated datasets
| Author/Title | PlumX | Altmetrics |
|---|---|---|
| P. Teleti, E. Hawkins, K.R. Wood (2023) Digitizing weather observations from World War II US naval ship logbooks, Zendo, doi:10.5281/zenodo.7781108 | ||
| S. Middleton J. Ziomek (2021) GloSAT Historical Measurement Table Dataset, Zenodo, doi:10.5281/zenodo.5363456 |
NOTE: Publications metrics kindly provided by PlumX and Altmetric.com